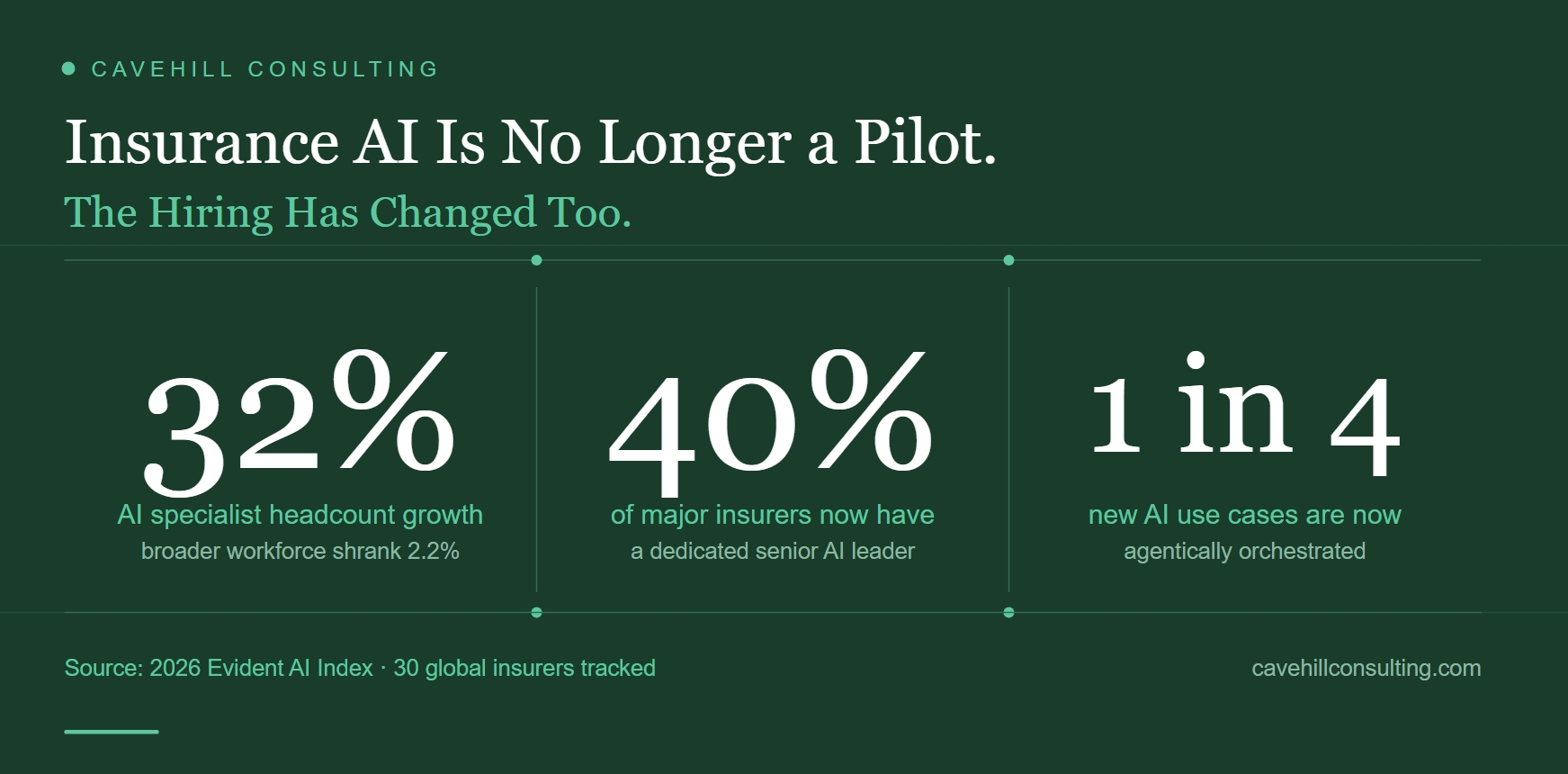
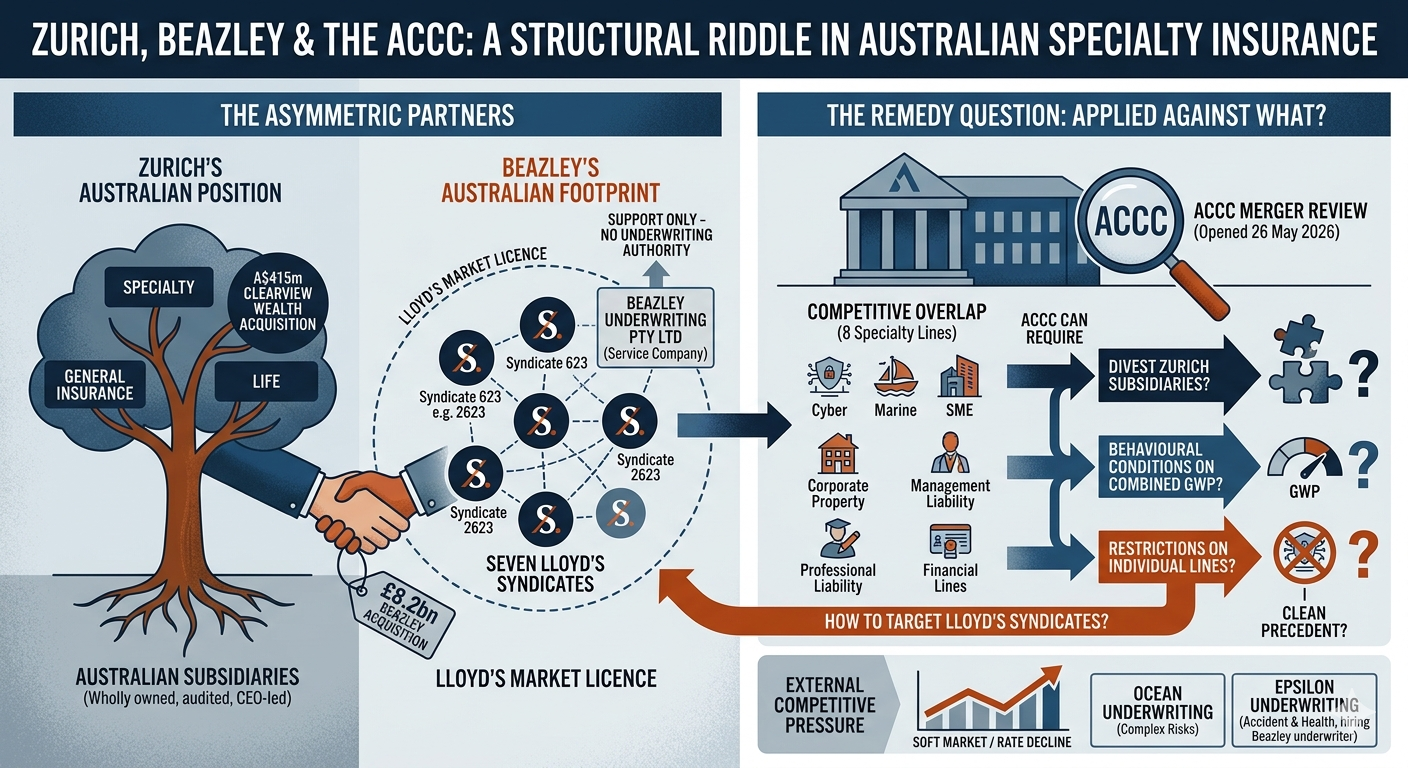
What Capture-at-Source Actually Means for a Lloyd's Underwriter | Cavehill Consulting
What Capture-at-Source Actually Means for a Lloyd's Underwriter | Cavehill Consulting
The phrase "capture-at-source" has become the accepted framing for CDR architecture. The LMA Data Council uses it. The consultants use it. The vendor presentations use it. Fewer people can explain precisely what it means at the workflow level — the point where a Lloyd's underwriter is actually looking at a risk, making a decision, and the data that decision generates needs to end up in a structured, ACORD-compliant Core Data Record.
This is that explanation.
What capture-at-source is not
Capture-at-source is not a technology feature. It is not a field mapping exercise. It is not something a policy administration system does automatically once the CDR data model has been configured.
Capture-at-source means that the structured data fields required by the CDR are populated as a natural output of the underwriting workflow — not extracted from a document, not re-keyed from a broker slip, not generated by an AI tool reading an MRC after the fact.
The difference matters because any process that generates a CDR output without changing the upstream workflow is, by definition, a retrospective extraction layer. It may satisfy the current CDR release requirement. It will not scale as the incremental release schedule advances from Treaties to Claims and DUA to full Placing CDR.
Where the data actually comes from
The source of the CDR data is the submission and negotiation workflow. Bind is the point of confirmation, not creation. A CDR generated from the bound document is a compliant CDR. It is not a capture-at-source CDR — because the data was created in the underwriting workflow and extracted from a document, rather than captured in structured form as the workflow proceeded.
The operational consequence is that every CDR generated this way requires a human to review and validate the extracted fields. At low volumes, this is manageable. At the volume of a Lloyd's syndicate writing hundreds of risks per month across multiple classes, it is a permanent operational overhead that does not reduce as the programme matures.
What the architecture requires
A genuine capture-at-source architecture requires three things. First, the submission workflow — the system the broker uses to present the risk — must capture the required ACORD fields in a structured format rather than a document. This is not exclusively the syndicate's problem to solve; it requires the broker platform to support structured data submission. The market is moving this direction, but it is not uniform.
Second, the underwriting system must capture the negotiation workflow in structured fields — line size, terms agreed, conditions — as the underwriter works. This is the most technically demanding requirement because it means the underwriting workbench must be designed for the Lloyd's placement workflow specifically, not adapted from a P&C workflow.
Third, the bind process must validate and confirm the structured data from submission and negotiation rather than generating new data from the bound document. The CDR is then a confirmed record, not an extracted one.
This is what the LMA Data Council means by capture-at-source. It is also why the architectural decision about which systems support which parts of the workflow matters more than any individual platform capability.
For a practitioner conversation about what capture-at-source means for a specific book of business or placement workflow, contact Grant.Bodie@CavehillConsulting.com.
Recent News
Our Latest Stories.